

For a child, responsive relationships are everything,
and they begin with interactions.

These interactions have a name: conversational turns.

The science is clear:
Conversational turns are among the most
predictive metrics of child outcomes.

The time is now:
Educators deserve innovative
professional supports.

Whatever you call it, this is the technology that's measuring interaction and transforming early childhood education.



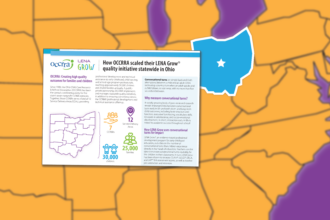


LENA’s impact is powered by organizations like yours
CCR&Rs, state agencies, Head Start/Early Head Start programs, libraries, and more are using LENA’s evidence-based programs to transform children’s futures. Click or tap on any state below to explore our work there.
Or explore our United States and world maps to see the 500+ organizations using LENA in 40+ countries.